
The Z.ai Playbook
Zixuan Li on the Chinese AI ecosystem
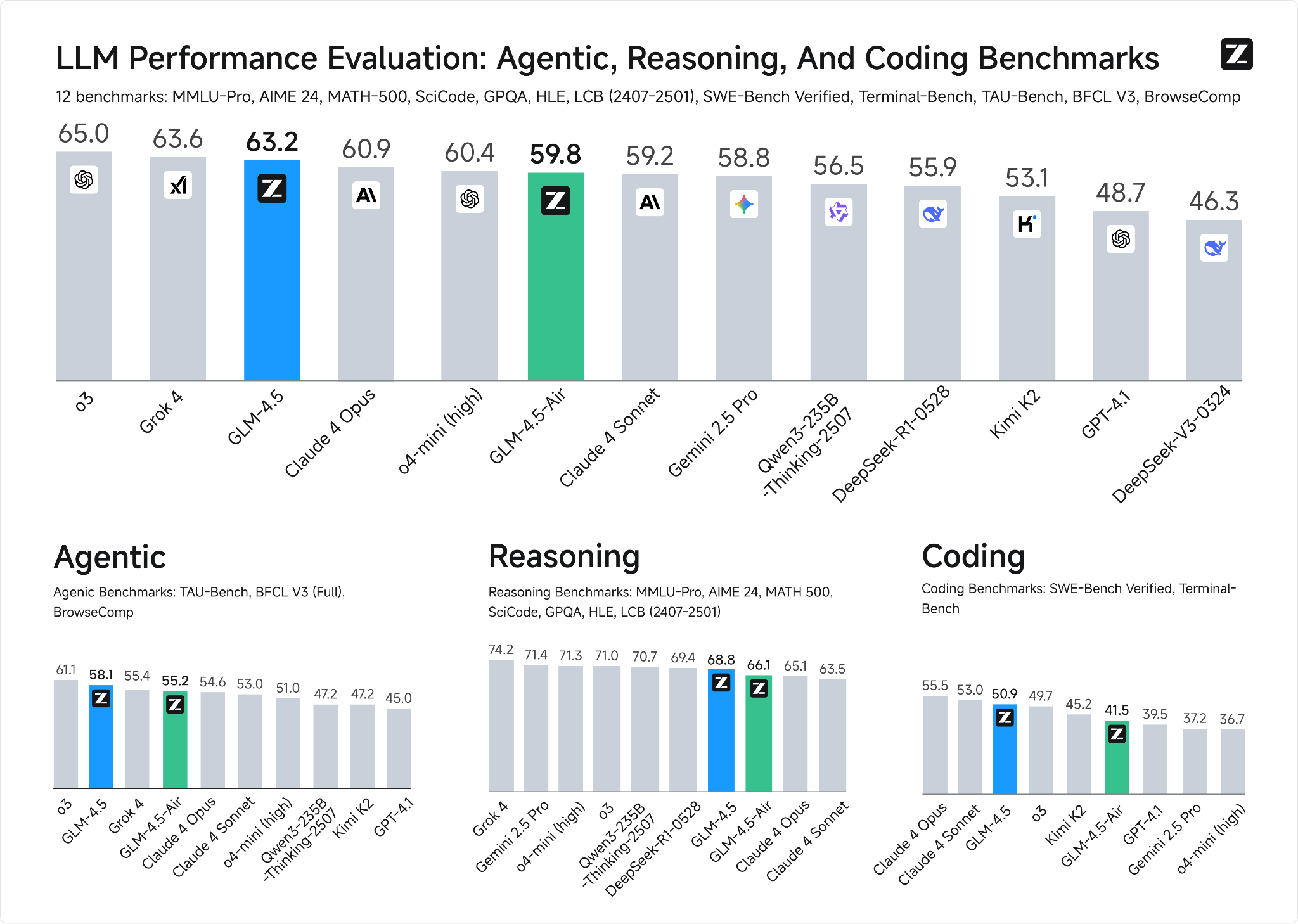
Zixuan Li is Director of Product and genAI Strategy at Z.ai (also known as Zhipu 智谱 AI). The release of their benchmark-topping flagship model, GLM 4.5, was akin to “another DeepSeek moment,” in the words of Nathan Lambert.
Our conversation today covers…
What sets Z.ai apart from other Chinese models, including coding, role-playing capabilities, and translations of cryptic Chinese internet content,
Why Chinese AI companies chase recognition from Silicon Valley thought leaders,
The role of open source in the Chinese AI ecosystem,
Fears of job loss and the prevalence of AI pessimism in China,
How Z.ai trains its models, and what capabilities the company is targeting next.
Co-hosting today are Irene Zhang, long-time ChinaTalk analyst, as well asNathan Lambert of the Interconnects Substack.
Listen now on your favorite podcast app.

The Z.ai Model and Chinese Open Source
Jordan Schneider: Zixuan, could you introduce yourself?
Zixuan Li: Hi everyone, I’m Zixuan Li from Z.ai. I manage a lot of things, like global partnerships, Z.ai chat model evaluation, and our API services. If you’ve heard of the GLM Coding Plan, I’m actually in charge of that, too. I studied AI for science and AI safety at MIT, where I did research on AI applications and AI alignment.
Jordan Schneider: Let’s do a little bit of Zhipu AI’s backstory. When was it founded? How would you place it within the broader landscape of teams developing models in China?
Zixuan Li: Zhipu AI and Z.ai were founded in 2019, and we were chasing AGI at that time, but not with LLMs, but with some graphic network or graphic compute. We did something similar to Google Scholar called AMiner. We used that type of thing to connect all the data resources from journals and research papers into a database. People could easily search and map these scholars and their contributions. It was very popular at that time.
However, we shifted to the exploration of large language models in 2020. We launched our paper, GLM, in 2021. I believe that was about one year ahead of the launch of GPT-3.5, so it was a very, very early stage. We were one of the first companies to explore large language models. After that, we continuously improved the performance of our models and tried a new architecture. GLM is a new architecture, actually, but we’re going to explore more in the future.
I believe we became famous with the launch of GLM 4.5 and 4.6 because they are very capable in coding, reasoning, and agentic tool use. That’s more useful compared to the previous version. People may know us through Cloud Code, KiloCode, and other tools. We need to combine with these top products to gain fame.
Nathan Lambert: What does it take to transition from the models you were early to developing into things that get international recognition? I’ve known of Z.ai and your work for years, and then it’s like a snap of the fingers, and suddenly, this model is on everybody’s radar that’s paying attention. Did this feel like something that was going to happen overnight, or what does that feel like when you go through it? How do you get to that moment? There are a lot of people that want to do that at their companies.
Zixuan Li: That’s a very interesting point. In 2024, everyone was interested in the Chatbot Arena. We saw GPT-4 and Gemini performing very well there. That was our interest because we pay attention to end-users’ experience, such as deciding which answer they prefer when presented with two options. We did a lot of work on that and performed very well on the Chatbot Arena, ranking maybe sixth to ninth.
In 2025, with the launch of Manus and Claude Code, we realized that coding and agentic functions are more useful. They contribute more economically and significantly improve people’s efficiency. We are no longer putting simple chat at the top of our priorities. Instead, we are exploring more on the coding side and the agent side. We observe the trend and do many experiments on it. We need to follow the trend and also predict the future.
Jordan Schneider: Let’s talk a little bit about the talent and the internal culture that allowed you to put out GLM 4.5. What do you think is different about, or what distinguishes, Z.ai from other labs both in the US and China?
Zixuan Li: First of all, we are more collaborative inside the company. Everyone is working on a single target. We have the heads of separate teams — the pre-train team and the fine-tune team — but they are working very closely. They sit next to each other, working on the single goal of trying to build a unified reasoning, agentic, and coding model. As we illustrated in our tech report, we first built three separate models (teaching models). We then distilled those three into one single model, GLM 4.5. That was our goal, and I believe that is how we built GLM 4.5 more efficiently compared to other companies, which are very young.
Another point is the talent. I believe that nowadays, the head of the team needs to do the research and the training themselves. You cannot let others do this stuff for you. Why is that? Because things change so fast. Maybe during your training, Claude 4 or GPT-5 comes out; anything can happen. You need to feel the trend yourself. You need to combine the results from experiments and the trends — what’s going on within your competitors’ teams — to feel the move yourself. It’s super important. Even our founder does the experiments himself and looks at the papers. You need to do things simultaneously, not just set goals for people and let others do the work for you.
Nathan Lambert: It seems very fast-paced. Before we started recording, you also mentioned that there are a lot of PhD students involved. I was just wondering if these are people who are actively pursuing their PhDs, new graduates, or a mix of all of them. I work at a research institute, which is very open-source, and we have many full-time students who are part of it. When you look at other closed labs in the US, there isn’t nearly as much intermingling with academic institutions. That could be a really powerful thing if you have this, because there is extreme talent there. I’m just wondering if you feel like there’s an open door between some academic institutions and your work.
Zixuan Li: Definitely. There are a lot of ongoing PhD students here, and I believe they are simultaneously pursuing their academic goals and working on GLM, but they can combine them. If you are doing a truly innovative job, like training a unified agentic coding model, it’s one of your greatest achievements ever. People won’t say, “I need to do another research, let me finish this first, and then I’ll go back to GLM.” They will try to treat GLM as their single biggest achievement. Everyone is really devoted to this stuff. We hardly see anyone who isn’t devoted to training GLM.
Jordan Schneider: What does the talent market look like in China right now? What’s the hierarchy, what are employers looking for, and what is the talent looking for?
Zixuan Li: On the research and engineering side, companies are looking for papers, GitHub code, competition performance, and your experience using GPUs and training models. For the non-technical side, they’re looking for how you will grow the model’s performance and expand the brand. If you’re going to be a product manager, for example, your vision in this area and how you execute are very important. The requirements are pretty similar across the board.
You mentioned hierarchy. In terms of hierarchy, large companies choose people first because they have more money and can pay more, companies like ByteDance and Alibaba. For startups like ours, we need people to fight together. You need to fight against other competitors and drive yourself to finish goals because you don’t get paid as much. You need ambition. You must truly enjoy working with really young, talented people and trying to build something like GLM that seems to come from nowhere and beat other competitors’ models.
Nathan Lambert: How big would you say the number of people actually training the model is? In the US, it’s accepted that the core research and engineering staff normally doesn’t get to be more than one to two hundred people at places like OpenAI. There’s a lot of support around them in terms of product and distribution. Do you feel like this is similar?
Zixuan Li: The core small research team is similar, about 100 to 200 people. I think that’s enough because you need to be focused, right? There are other people preparing data and doing product work, but for the core team, you don’t need that many people. You need to stay focused, and these people need to be really talented; they cannot make many mistakes.
Irene Zhang: Is that different at bigger companies?
Zixuan Li: For bigger companies, there might be different groups. They have more GPUs and can do more exploration. For example, at ByteDance, they are chasing top performance not only in text generation but also in video generation, speech, and other areas. They can allocate resources to multiple teams. But inside these teams, I think the core members are still the same — maybe 10 to 20, and the other 80 or 100 people are doing the training or data preparation work.
Jordan Schneider: What’s the thought process behind so many Chinese models open sourcing in recent years?
Zixuan Li: First, I think we need to devote more to the research area. Llama’s doing this, Qwen is doing this, and Kimi’s doing this. We are also doing this. We want to contribute more to academia and the exploration of all possibilities. I think that’s our top priority.
But beyond that, as a Chinese company, we need to really be open to get accepted by some companies because people will not use your API to try your models. Maybe they deploy on Fireworks, maybe they use it on Groq, or maybe they download to their own chips. It’s not easy to get famous in the United States because people just don’t accept your API. They need to be stored in the US. I think it’s necessary to be open right now for people to use our models.
Nathan Lambert: This is what our company does. It’s like where I work — I wouldn’t be able to sign up for the API service at the enterprise level. But I distill from multiple Chinese models when I’m training. I’m using multiple models and might come across this, so it’s not surprising, but it’s good to articulate it.
Zixuan Li: We also learned from DeepSeek because our flagship model was closed source back in 2024. But when DeepSeek R1 launched, we realized that you can be really famous for open sourcing your model while getting some business return through API or other collaborations. You need to expand the cake first and then take a bite of it.
Jordan Schneider: Why is it so important for Chinese model makers to get famous in the US or achieve global adoption more broadly?
Zixuan Li: Because I think there’s a better ecosystem for developers and research still in the United States. You need to get accepted by the top researchers because if we don’t open source our models, we’ll never have an opportunity to join this conversation. It’s important because we learn from X, from YouTube, from Reddit every day, and all the Chinese tech media are also paying attention to US KOLs or influencers.
Jordan Schneider: This was very surprising, I think, to both Nathan and me — how recursive it was, where the Chinese media covers the Chinese models that the Americans are talking about. It’s a very curious trend.
Zixuan Li: Because you have people like Andrej Karpathy, Sam Altman, and Elon Musk. They not only talk about their own models but also what’s going on elsewhere. Everyone knows — if they post a tweet, everyone knows what’s going on, what models they’re picking, what preferences they have, their views on maybe Qwen versus Codex. All the social media will try to grasp their core ideas immediately. That’s very important. We also learned this from DeepSeek.
Frankly speaking, we used to neglect the importance of the global economy previously because we thought we needed to sell our products and APIs directly to Chinese enterprises. But nowadays, Chinese enterprises are still paying attention to the global brand and your global performance.
Irene Zhang: This reminded me of something I’ve been curious about. We know the conversation is recursive. We know that Chinese tech pays a lot of attention to what Silicon Valley is looking at. But is there anything about the AI debate or discourse in China that Western media tends to miss? In your opinion, are there any issues or debates or things that people are really interested in that people in the English-speaking discourse tend to not understand?
Zixuan Li: I just talked to a professor from Germany yesterday, and he mentioned some models that he knew people are talking about these days — Llama, Qwen, even Mistral — but not GLM. There are many people still unaware.
Nathan Lambert: This person’s a little out of date in the SF circles. More people are talking about GLM than Mistral and arguably Llama these days. You’ve made a lot of progress.
Zixuan Li: We’ve made a lot of progress, but we track the discussion on Reddit and other social media, and we still see a lot of people asking what GLM is. Is it a good model? Where does it come from? It comes from nowhere or similar stuff. We still need to do a lot of things because we only have 20,000 followers on X. People don’t have a very deep understanding of GLM compared to other models.
Nathan Lambert: I think DeepSeek has like a million. It’s remarkable.
Zixuan Li: Also, Mistral and Cohere get much more attention compared to Kimi and Z.ai. We still need to do better in our branding and our engagement in the technical community.
Jordan Schneider: You mentioned selling API access to Chinese companies. Tell us a little bit about adoption in China. What’s the sales process like? Do they all just have VPNs and use Claude? What’s it like trying to do enterprise sales in China?
Zixuan Li: You have two types of enterprises. One is companies that can’t use APIs because they need to deploy the model on their own chips. They cannot accept sending data to other companies — not even to Z.ai or even Alibaba. That’s a requirement for those companies. There are teams deploying DeepSeek for them — not from DeepSeek itself, but other companies can deploy DeepSeek for them. They usually build on top of the DeepSeek model with RAG, data storage, workflows, and other things.
The other type uses APIs — those are maybe tech companies and media companies. These companies accept APIs because they need to standardize their workflows. For API companies, they choose based on the balance between performance and price. ByteDance is doing great in that area. I believe ByteDance dominates the API services. Qwen is still trying to sell its APIs because Qwen 3 Max is a closed source version. If you’ve heard of it, they have open sourced some models but also keep some things closed source for selling.
For us, we have open sourced our flagship models, so we are frequently asked, “Why is your service different from the open source version? Because we can deploy the open source version ourselves.” We need a better engineering team, we need faster decoding speed. We need to do more on top of just having a good model. That might be our unique selling point. We need to do searches, we need to build our MCP. We’re trying to get a competitive advantage over other GLM providers.
Jordan Schneider: Is that annoying or fun?
Zixuan Li: It’s fun. It’s fun because I think it’s necessary to open source your models, so how you get a bite in that case is really important. We’ve been figuring it out for a long time, but recently we found that subscription is a good idea — a GLM coding plan. With subscription, your users become more sticky. They love this area because you don’t have to worry about how one prompt consumes tokens in your dialogue. Maybe inside Claude, a round of interaction will consume a million tokens, but you don’t have to worry about it. We’ll figure it out for our users.
Nathan Lambert: Do you think you have meaningful adoption there? Because in the US market, I could start using Claude, Codex, Gemini, and whatever all for free with some basic Cursor. I was wondering — are people in the US actively using this? Is this a growing market that you think you’re going to eat into? Qwen has one, and I might have tried it, but I’m always like, “Oh, I have my ChatGPT subscription.” I’m just wondering if, on the ground, it feels optimistic as something that is really shifting the needle.
Zixuan Li: It’s definitely very optimistic because we don’t have to persuade 50% of people to do this — maybe you only need 5%. But 5% is a huge market. If 5% of Claude users shift their model to GLM, it’s a huge market.
Nathan Lambert: It’s growing so fast, too.
Zixuan Li: But not just for Claude, because we’re trying new ideas like role-playing. Many people on Silly Tavern are using GLM and Janitor AI because we do very well in role-playing. We’re trying to have more markets — coding markets, chat markets. Maybe one day Meta will be using our model.
Jordan Schneider: All right, we’ve got to take a step back and explain role playing. What is it? How do you make a model that’s good at it? What are people using it for?
Zixuan Li: Before GLM-4.6, for models like GLM-4.5, we were relatively weak in role playing because we hadn’t trained on that kind of data. We needed to create some data and let the model follow the instructions. For role playing, if you have a very long system prompt and you don’t train on that kind of stuff, the model will forget who it is and forget all the instructions. It will just use its general performance to do the conversation. For a role-playing task, if given very long instructions, it must strictly follow those instructions and show more emotion or more specific behavior based on them.
Jordan Schneider: Just to be clear, this is people having a conversation, for example, saying, “I’m a Japanese pirate, I’m raiding the coast of Taiwan in 1570, and I want to plan an attack to defend the fort.” People write out like five pages of background.
Zixuan Li: We also tried something very interesting, like Family Guy. We have our own Stewie, and you just give a description of what the characher does and his history, and then you can create your own Stewie. We perform very well in text generation. If we had some speech model, we could recreate a Stewie there too.
Jordan Schneider: Was there a specific kind of pre-training data or RL that you needed to do to get this? How do you make a model that is really good at pretending to be cartoon characters?
Zixuan Li: It’s mainly post-training data.
On AI Optimism and Translating Chinese Memes
Jordan Schneider: There’s a big discussion of late in the US about people being worried that folks are falling in love with AI. There’s this whole discussion about AI psychosis, where ChatGPT, for example, convinces people who trust it too much to harm themselves. I’m curious about your broad sense of that type of discussion in China generally, and then internally in your firm, about the question of people using AI for emotional support.
Zixuan Li: I just read a post from OpenAI yesterday. They invited a lot of experts to try and train a model that is not addictive. They trained data to ask ChatGPT to say it’s an AI instead of saying it’s a human being, not letting people get attached to ChatGPT anymore.
But from a broader audience perspective, not many people at Z.ai are looking into this yet because our model’s capabilities are not there yet. If we had a model that could perform like GPT-5, then we could move on to removing the addiction.
Still, the performance is not on par with these top closed-source models, which we need to chase first. When we chase these models, we shift our focus to data collection and data preparation. Sometimes, the model behavior will change dramatically. If we do some similar things on our previous model, it will be outdated in the next version. Performance is still very relevant currently.
Nathan Lambert: I’m guessing this is somewhere in the rundown, but what is the balance of optimism versus fear of AI as a long-term trajectory in your lab versus China generally? I think there’s a very big concentration in the US of people who worry deeply about the long-term potential of AI, whether it’s a powerful entity or a concentration of power or other things. Then there are people who just think this is the most important technology ever invented, and we have to be really serious about it. I’m just wondering where on this spectrum you think the lab’s culture is, or if it’s not really something that’s debated, and you’re just focused on, “We’re building a useful thing, and we’re going to keep making it better.”
Zixuan Li: I think developers fear the most. When you use code, when you use Codex, you get that fear in a very concrete way. It can do all the tasks for you, especially for junior developers. For writers or other managers, though, I think it’s simpler because we already have SaaS and other technologies helping them. Large language models like ChatGPT are just another helper for them. So, I don’t feel fear coming from the general public, but specifically for developers and data analysts. They fear the most because they try out the new models and new products more frequently than the general public, so they can feel the power.
Many people use DeepSeek and other chatbots. DeepSeek can help you brainstorm ideas, polish your writing, or do translation for you, but they don’t believe that this work can replace them. But for developers, it’s a different story.
Jordan Schneider: What are the main fears? Is it just people’s jobs getting taken away? Or is it AI taking over the world? For the people who are worried, what exactly are they worried about?
Zixuan Li: Probably jobs being taken away.
Nathan Lambert: Those fears are pretty different than in the US. There’s definitely a huge culture — not a majority of the people, but a very vocal minority — that influences a lot of the thinking about the risks of AI well beyond just job loss. Job loss is almost an assumption for many people in the US, but there are added fears on top of this. I think that is a very different media ecosystem and thought ecosystem.
Zixuan Li: I definitely know about this because I lived there. Obviously, everyone at MIT was talking about how AI will change the world, not on the positive side, but on the negative side.
Irene Zhang: Why do you think this is? Is it that Chinese society is a little more practical, or is it just that job loss feels more imminent, or is it because it’s less of a market-driven economy?
Zixuan Li: I believe that people just know about DeepSeek. Maybe only 1 million people follow the latest trend, and a billion people do their work daily and are not impacted by AI. The more you learn about it, the more fear you have.
Irene Zhang: What is the vibe among these younger engineers you’re talking about? Specifically, the junior folks who are a little scared. I’m generally curious what gets them into this work in the first place and what makes them want to work at places like Z.ai?
Zixuan Li: At Z.ai, we lack people. There is no fear about losing jobs here because we have a lot of things to do. For other companies, especially large enterprises, they may have 10,000 people doing similar things, such as data analytics and back-end engineering work. They might think that if other people start using coding tools or agentic tools, maybe they only need 50% of their current staff.
They can do nothing, though. They need to wait for their bosses or the founders to make the decision, like what’s happening at Amazon. For layoffs, you can do nothing — you just wait for the results.
Irene Zhang: I’d like to ask about translation because Z.ai’s models are very strong in making very contextually rich translations from Chinese to English and deploying them onto social media. Could you talk a bit more about the process behind that, if you know? What is the secret sauce to translating memes?
Zixuan Li: We are doing very well in translation, especially the translation between Chinese and English. I think we are on par with Gemini 2.5 Pro. You mentioned memes — memes are one of our weapons because we prepared the data and understand the culture. We can even translate emojis. For example, if you enter a sentence talking about AI and you use a whale emoji to replace DeepSeek, we might translate this back to DeepSeek. However, if the sentence is actually about animals, we will translate the emoji into “whale.” We understand the context.
Irene Zhang: Is this because Chinese internet talk is just so cryptic?
Zixuan Li: Yes, Chinese netizens are very novel. They sometimes use emojis. People also use abbreviations, so all those things need to be translated correctly.
Jordan Schneider: I remember a few years ago there was all this discussion that it was going to be really hard to train Chinese models to speak colloquially because all the data is behind walled gardens. For example, Tencent has the Tencent data, Xiaohongshu has the Xiaohongshu data, and Alibaba has its own data. Was that a problem for you guys doing this more colloquial, internet-speak work? Or is there enough out there that you can just scrape stuff and figure it out?
Zixuan Li: We need synthetic data. We do not have the actual data — we cannot scrape WeChat, but we know what people are talking about, especially in the public area. In the open area, we can observe what’s going on on Xiaohongshu and on TikTok, for example. We especially pay attention to their comment area because people are very novel in their comments.
When the “TikTok refugees” situation happened, we actually benefited from it because more people and more software needed auto-translation. We are trying to conquer some large customers through our translation capabilities.
Jordan Schneider: Does anyone train on danmu 弹幕 data [Ed. the rolling comments that appear on top of Bilibili videos]?
Zixuan Li: Definitely. We are trying to collect memes from everywhere, especially for our vision model, because memes are always in image format. We are trying to understand them with our vision model. I think it’s very interesting and also very necessary because if you cannot translate the comment in a very accurate way, customers will not purchase your model.
It’s unlike YouTube. If you use YouTube’s auto-translation, it won’t grasp the exact meaning. People just need to understand, “Oh, this English version is about this, and I can read it in Chinese. 80% is enough for me.” But for apps like X, Reddit, Xiaohongshu, or WeChat, you need to understand 100% of the comment area.
Nathan Lambert: Is it a challenge to balance data across different cultures? Since you are marketing to Western users as well as having your domestic market, is that a technical challenge to feel like you have to do both excellently?
Zixuan Li: It is a challenge. We can do very well in Chinese and English, and we are trying to explore more in French and even Hindi. We can perform very well in, I believe, about 20 languages. Beyond that, we are still exploring the data and the software. We need to register on their software to see what people are doing out there. Sometimes it’s hard to figure out. We are trying to learn from Gemini and GPT-5 why they do so great in translation.
Domestic Training and Hitting the Data Wall
Jordan Schneider: Do you guys train outside of China as well, or only on domestic clouds?
Zixuan Li: We do the inference outside China, but all the training is going on here.
Jordan Schneider: How do you feel about Huawei chips and software? Are they going to make it?
Zixuan Li: We are going to use them because we have multiple models, like GLM-4.6 and the upcoming 4.6 Air, as well as our previous version. We need to find the best use case for all sorts of chips: domestic chips and Nvidia chips. We need to classify the use case. One customer may need 30 tokens per second, and another customer may need 80 tokens per second. For one customer or one use case, some chips are enough, and for others, we need better chips and better inference techniques.
Irene Zhang: Do you try to do any API sales or just enterprise sales in general outside the US or China?
Zixuan Li: We have two platforms. Inside China, our platform is called Big Model, which is a simple translation of “large language model.” It’s BigModel.cn. We also have Z.ai, which is our overseas platform. I’m actually in charge of API Z.ai. All of our services are hosted in Singapore. I’m an employee of a Singaporean company.
Irene Zhang: Do you see much demand for Z.ai coming from non-US countries, like other countries?
Zixuan Li: We see demand from a lot of countries — India, Indonesia, even Norway and Brazil. However, it depends on who’s using Reddit and X, because we basically grew our user base on X, Reddit, and some on YouTube. We are trying to expand to platforms like Telegram, which might shift the proportion of our users. India and Indonesia are huge markets. More revenue, however, comes from the US compared to other countries because they pay more. They buy the Pro plan or Max plan instead of the Light plan. In terms of users, India has the most, but the US market generates 50% of our overseas revenue.
Irene Zhang: Building off of what we were talking about earlier — that walled gardens didn’t matter — does Z.ai have any thoughts about doing AI search on the Chinese Internet, and what that will look like in China, where there increasingly is no unified, open internet?
Zixuan Li: That’s a challenge for us product builders. Google doesn’t have a search API, and Bing is trying to stop its search API. There are other third-party providers like SERP, which basically just scrape the data — they quickly send a request to Google and scrape the page. This is also very challenging for builders like Perplexity and even ChatGPT.
We need to rely on the technical side, nowadays using our own technology or trying to gather multiple resources from different platforms. That is very reasonable. There are other technologies, like manuscript, that just browse the Internet themselves without using an API. That’s more doable these days. When you want to see multiple resources and try to distinguish the best use case or the best resources, you need to really log into an account and see the data yourself, read the page yourself, instead of just using whatever API gives you.
Nathan Lambert: Where are you planning to take your models next?
Zixuan Li: Right now, we are exploring on-policy training and on-policy reinforcement learning. We are quite mature in off-policy reinforcement learning, but for on-policy learning, we still need to explore more. Also, multi-agents.
When you look at Z.ai chat, it actually acts like a single agent. One model does the search, comes back, does another round of search, then comes back, and it can generate slides, a presentation, or a poster, things like that. But it’s all performed by a single actor, the one GLM-4.6
Nathan Lambert: Do we think we have to change our models a lot in order to do this? So much of 2025 has been changing the training stack away from “we are a chatbot” to “we are an agent.” What do you think we should change the most about our models, given that the faster model, like the Air model, might be more useful because you can have more of them?
Zixuan Li: That’s the reason why we need to do a very solid evaluation because we have different product solutions. Currently, the single agent works very well on our platform. We need to do more to try out different ideas and see whether we can improve the speed and performance with a multi-agent architecture and other possibilities. For single agents, it has better context management because you have the best model that can see all the context ahead of the current conversation and follow the instructions up to that point. For multi-agents, however, you need to compress the context for each agent, and that might lose some context or information.
Nathan Lambert: Or the orchestration is hard. If you give four agents the same context, they might all try the same thing, and they might not work together well.
Zixuan Li: Yes. If even one agent has a hallucination, it will ruin all the research. We are also trying to make a longer context window and a longer effective context window. We all know that you can say your model can do a one-million context window, but it actually performs very well only inside 60k or maybe 100k.
Nathan Lambert: You can release whatever size of context model you want, but the question is whether or not it actually works.
Zixuan Li: Exactly.
Nathan Lambert: How much do you think it’s going to be scaling the kind of transformers that we have — making the long context better, just improving the data — versus if there are fundamental walls that this is approaching? It’s kind of the low-hanging fruit question. Do you just think there’s a ton to keep improving, or is it kind of easy to find the things to do, and you just don’t have time?
Zixuan Li: It’s not easy. We believe it’s the architecture thing. Data can improve performance, but it cannot cross the wall. There is a wall. We need a better architecture, better pre-training data, and better post-training data.
Nathan Lambert: Do you think you’re starting to hit this wall, or do you kind of see it coming already? Is this something you’re forecasting, or are you seeing, “Oh, this specific thing — data alone is not solving it for us”? People in the US who are training these models just don’t talk about it; they say, “I can’t say.” I’m curious. The models I train are smaller — I think our biggest model is about 30 billion scale. When you scale up, you start to see very different limits to what’s happening.
Zixuan Li: We need to do some experiments. GLM is a 355-billion-parameter model, but we cannot do experiments with this large model. We need to do experiments with some smaller models, maybe 9 billion or 30 billion parameters, and test our hypothesis. Ninety percent of the time, we just fail, because you cannot win every time with experiments. You need to do a lot of scientific work to finally get the right answer.
If you are talking about whether the GLM-4.6 architecture will hit the wall, there is actually a wall. We need to shift our focus and start from maybe a new architecture or a new framework for doing this stuff.
Nathan Lambert: It sounds like these bigger runs were not necessarily barely making it, but definitely stressful for you.
Zixuan Li: Yes, it’s stressful. We are going to use some engineering solutions to try to compress the text windows to make our users happy. You don’t normally need one million tokens yet. If it cannot perform very well, you can compress the context window to 60k or 30k to make it work.
Jordan Schneider: You mentioned earlier that all the inference is abroad, but training is at home. What’s the rationale behind that decision?
Zixuan Li: The rationale is very simple — we provide services to overseas customers. I think it’s a requirement to store the data overseas. That is a very strict policy for our Z.ai endpoint. We change that privacy policy every month to make it stricter and more coherent with people’s expectations.
For the training, I think it’s simpler because we don’t have many resources. We only have these resources, and we need to utilize them.
Jordan Schneider: But doing it on Azure or AWS in Malaysia or Singapore — is that too expensive, or too slow? Do you guys already have enough chips at home? What’s the thinking there?
Zixuan Li: I don’t think it’s very slow — it’s fast because we change the location of not only the GPU but also the CPU and the database. If they are all in Singapore, it is still very fast. If you have to go back from Singapore to mainland China and then go back to Singapore, it will be slow.
On the training side, I think it’s very simple. We’re not OpenAI or Anthropic; we don’t have to choose between Amazon and Google and their own infrastructure. They are doing very complicated things. For us, I think we are still in the initial stage. We don’t have many complicated structures with these large inference providers, so things are still simple here.
Jordan Schneider: For now.
Zixuan Li: For now, yes.
Jordan Schneider: Irene or Nathan, any more training questions before we wrap up?
Nathan Lambert: Only sensitive questions that I don’t expect to have an answer to: How big is your next model? How many GPUs do you have?
Zixuan Li: For our next generation, we are going to launch 4.6 Air. I don’t know whether it will be called Mini, but it is a 30-billion-parameter model. It becomes a lot smaller in a couple of weeks. That’s all for 2025.
For 2026, we are still doing experiments, like what I said, trying to explore more. We are doing these experiments on smaller models, so they will not be put into practice in 2026. However, it gives us a lot of ideas on how we are going to train the next generation. We will see. When this podcast launches, I believe we already have 4.6 Air, 4.6 Mini, and also the next 4.6 Vision model.
Nathan Lambert: A good question is: How long does it take from when the model is done training until you release it? What is your thought process on getting it out fast versus carefully validating it?
Zixuan Li: Get it out fast. We open source it within a few hours.
Nathan Lambert: I love it.
Zixuan Li: When we finish the training, we do some evaluation, and after the evaluation, we just release it. We don’t send the endpoint to LM Arena or to other analysis companies to let them evaluate it first and then release the model. We don’t have that. We also don’t have a “nano banana” thing to try and make it famous before it’s launched because we are very transparent. We believe that if you want to open source the model, the open source itself is the biggest event.
Irene Zhang: Do you try to time the release with a market event or anything?
Zixuan Li: We are trying to do some marketing from my side, and I want to make the rollout longer. I want a week for me to collaborate with inference providers, benchmark companies, and coding agents, and let everyone trial the model before it’s released.
From the company’s perspective, if open source is the most important thing, you only need to prepare the materials for the open source itself. You need the benchmarks and maybe a tech blog. It is very stressful for me because I need to negotiate with multiple partners within several hours. “We have a new model coming in two hours, maybe three hours. Maybe you are sleeping, but this is huge.” We don’t give enough time for people to connect to the model or do the integration, but we’re trying to post your tweet afterwards.
Jordan Schneider: Now, in America, we have our own thing, 002.
Zixuan Li: What is 002?
Nathan Lambert: Midnight to midnight with a two-hour break. It’s so dumb.
Zixuan Li: Hours vary a lot, even inside the company. Someone might leave the company at 7 p.m., while someone else will never leave the company. For me, I work 18 hours a day because I need to negotiate with US large firm CEOs or the founders of coding agents. I need to discuss with Fireworks, with LM Arena, and with Kilo Code CEOs. I have to follow their time and do meetings, sometimes at 2 a.m. or 3 a.m. That’s all possible.
For our researchers or the engineering team, your brains can only work maybe eight hours a day. If you feel tired, you need to get some rest. It’s impossible to ask a top researcher to work 24 hours a day. That would mean you are either working inefficiently or you are just attending meetings. But if you want to read papers, do experiments, and write code, eight hours is enough.
Irene Zhang: That’s very sensible.
Nathan Lambert: My PhD advisor always said that you can completely change the world if you do four hours a day of top technical work. Just go walk in the sun after that — you did a good job.
Irene Zhang: How do you explain the value of your work to, let’s say, high school kids in Beijing? Or your grandmother?
Zixuan Li: It’s hard. I can only say I do something similar to DeepSeek. Everyone in high school, and even in kindergarten, knows about DeepSeek.
For developers, it’s simple: we are one of the best coding LLMs you can find, especially in China. But for high school students, they always ask, “We have DeepSeek, what are you doing? Why do we need you? Are you doing a similar thing, or are you better? Are you faster?” That’s very tough.
We still need to improve the model performance. That’s the top priority. Product experience is the second. Without a solid model, nobody will pay attention to you. If we are at the same level, only the most famous one gets all the attention.
Irene Zhang: So you think the salience of AI models, generalized across society, came straight out of DeepSeek and the kind of nationalism associated with that?
Zixuan Li: There is a hype. They got so famous, even in China, so we are unknown even here. I believe a lot of students in Tsinghua University haven’t tried GLM or haven’t even heard of this company. Everybody knows the famous names, but not everyone goes to this building to visit Z.ai, right? DeepSeek is all over the news and social media, so it’s really tough to explain our contribution and our value.
Irene Zhang: Do you think Chinese society is starting to find AI to be more valuable, or is it getting scarier than valuable?
Zixuan Li: We are not there yet. AI is not so strong as to make people fear it because there is still hallucination, and it’s still not always following instructions. There are still a lot of issues to solve before it becomes more fearful or terrifying for people.
Jordan Schneider: We end every episode with a song. Does Zhipu have a theme song, or what do people listen to when they code around the office?
Zixuan Li: Actually, no. Our founder loves running, but music not so much. He is a pro in the marathon. The founder of Moonshot really loves music, but our founder doesn’t have much interest in it. For our anniversary, we have a half-marathon to celebrate.
Nathan Lambert: I’ve got to go do this. I’m going to go run the Z.ai half-marathon next year.
Correction: A section of this transcription originally recorded Zixuan as saying, “In 2025, with the launch of Moonshot’s Kimi Chat (Kimi K2 model), we realized that coding and agentic functions are more useful.” It is, in fact, “In 2025, with the launch of Manus and Claude Code, we realized that coding and agentic functions are more useful.” The transcript has been updated
Great get. Chinese AI workers get a bit mythologised when you only read about them through translated articles from before their model hit the big time. Zixuan just seems like a cool, normal guy.
This is great, really excited you got someone from a Chinese lab on the show! Would also be very excited to her from people in the tech giant labs (Alibaba, ByteDance, Baidu, Tencent, etc.) if they wanted to come on the show.